.png)
 3 years ago
198
3 years ago
198 BOOK THIS SPACE FOR AD
ARTICLE AD![]()
In working my way towards learning the various, different bug types and their complexities, I gained a better understanding of how the basic concepts build up to form the systems, as we know them, how they work and sometimes lead to security issues.
This piece tries to put together, the various elements that come together in explaining subdomain takeovers, right from the fundamentals.

Each website has a unique domain name. FQDN stands for Fully Qualified Domain Name, which is basically the domain name that we use and this is registered with our DNS registrar (A company that manages the reservation of internet domain names, more).
An FQDN comprises of 3 segments: hostname, second-level domain and a top-level domain (TLD). For example:
Here, “www” is the hostname, “google” is the second-level domain and “com” is the top-level domain.
Fun-fact: All the domain names require a trailing period at the end. The trailing period is required by the Domain Name System protocol to indicate the end of the address, however, modern browsers do that for us so it’s not a general concern anymore.
DNS stands for Domain Name System, to share an analogy, can be resembled to that of a phone book wherein the contact number of a known person is mapped with their name, one in an entry. Likewise, DNS servers hold these entries of various domains with the IP of the servers that host them, making them an internet-wide accessible directory of domain names mapped to their I.P.(s).
DNS queries can be divided into 2 major forms:
FDNS : Forward DNS queries, which are the ones who resolve the domain name for a request to its IP address.RDNS: Reverse DNS queries, are DNS queries but they resolve the IP address back to its domain name.* These queries work by querying DNS servers for a PTR (pointer) record. If the server does not have a PTR record then it cannot resolve a reverse lookup request. PTR records reverse the IP address segments (192.168.0.1 -> 1.0.168.192) and append “.in-addr.arpa” (for IPv4, and “.ip6.arpa” for IPv6) at the end before storing them.
There are 3 major types of DNS servers:
DNS Resolver serverDNS Root serverDNS Authoritative serverDNS Resolver Server:
Stub Resolver: A Stub resolver is a software component, which works from the endpoint. Whenever a machine requires to make a DNS request, the stub resolver is that software component which makes these requests and serves back the response.Recursive Resolver: The internet consists of more than 50 million devices today, and at the root of the hierarchy, the internet uses exactly 13 DNS root servers, which are basically clusters consisting of many computers. To suffice for the enormous amount of traffic generated over the internet, there are plenty of Recursive Resolvers. A DNS Recursive Resolver, is basically a server which handles these incoming requests from the stub resolvers to further query the actual DNS servers. To bring the original analogy, these servers can also be considered as the people who use a telephone book.** One of the major reason for their existence is to reduce the load on the actual DNS servers. In layman terms, these recursive resolvers work as load balancers and have their own cache/storage of these DNS bindings, which is first queried upon encountering any DNS request and only if they do not have the desired query, are these queries forwarded to the actual DNS servers.
DNS Root Server
Root servers are the top-most level, in a way, the backbone of the internet. The resolution of domain names, works in a hierarchical order through DNS zones. The root servers contain the records for authoritative servers of all TLDs. There are in all, 13 root servers (or clusters of servers).
It’s because of the limitations of the original DNS infrastructure, which used only IPv⁴¹ containing 32 bytes. The IP addresses needed to fit into a single packet, which was limited to 512 bytes at that time. So, each of the IPv4 addresses is 32 bits, and 13 of them come to 416 bytes, leaving the remaining 96 bytes for protocol information. (Source)

DNS Authoritative Server
As the name suggests, these server are authoritative because they have the authority over different top-level domain spaces. When a recursive DNS server doesn’t have a cached response for a DNS query, it proceeds to query these top-level DNS servers, and the server which has the response for that particular query, is called the authoritative server. To relate with the original analogy, these are the servers which publish the telephone book, or in this case, the DNS service, in different regions.

To know more about the location of these root DNS server clusters, take a look at the links here and here. You can look at the various locations where these DNS servers are maintained and also the authorities who maintain them.
DNS Records are the very configuration files which contain the domain to I.P. mapping. Following are the major type of DNS records:
A Record: If you’ve ever edited the host configuration file on linux/windows systems then that is how an A-record is. On Linux systems, this file can be found at /etc/hosts location and in Windows systems it can be found at C:\Windows\System32\drivers\etc\hosts. These files have pretty basic mapping wherein each new entry begins with an I.P. address and a domain name, separated by a tab space. A records are used for IPv4 addresses only.
As you can see below, I do have some mappings of some Hack The Box machines that I have worked on, inside my /etc/hosts file. This is generally how an A-record looks like.
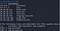
Querying A record for google.com (linux):
$ dig a google.com +noall +answer
Here, the flag “+noall” mean to disable all the output followed by “+answer” flag stating to print out only the answer to the query for the record. By default the dig command queries the A record, hence the response shows the A record.

2. AAAA Record (quad A): Just as A records are used to store the mappings for IPv4 I.P.(s), the AAAA records are used to store the mappings for IPv6 I.P.(s) and their domains.
Querying AAAA record for google.com (linux):
$ dig aaaa google.com +noall +answer

3. CNAME Record: Looking at subdomain takeover bug, CNAME records are the one that’ll interest us the most. These are also known as “alias records” which is because often times we point a (sub)domain to external hosting service providers such as AWS (S3), Github Pages, Wix or even Azure Cloud Apps. In this case, one (sub)domain maps to another (sub)domain rather than the A and AAAA records where an I.P. was mapped to a domain name.
A CNAME lookup performs two queries to reach the final address. When a DNS query returns a CNAME record, the server replaces the name with canonical name (the target domain/FQDN of the CNAME response) and looks up the new name.

There are some other record types which aren’t of much significance here, but references for further reading can be found in the “Further Reading” section at the bottom of this page.
FQDN is the main domain which is used to address a particular website, served through a web server. A sub-domain is a part of this FQDN, or the main domain name. It can be used to serve for various purposes like navigating to different sections of the main website or integrating different functionalities (such as customer support software etc.) in an isolated manner.
An example of a sub-domain would look like:
drive.google.com
Now, subdomains can either be hosted independently on a server, on the same server as the FQDN or on third-part hosting services such as Github Pages, AWS Cloudfront, Azure Cloud Apps, Heroku, Amazon S3, Readme.io and other services.
The vulnerability arises when the applications or the services running on these subdomains are taken down. Usually, the DNS entries for the subdomains are not removed and that is the origin of this security issue. Now whenever a subdomain is pointing to a third-party hosting service like the ones mentioned above, we can use the ‘host’ command utility to find out the address or the Canonical name.
Syntax:
$ host test.domain.com
The response should look something like this:

The same can be achieved using the ‘dig’ command.
Syntax:
$ dig cname sub.domain.com

This reveals that the given subdomain is using Github Pages to host its functionalities. Now we just need to make a repository with the name that is used in the CNAME record and edit the setting of the repository to use a custom domain name, which is our original subdomain. More details on the “how” can be found in the blog — here.
Hunting
First step is finding the subdomains on your target, for which my preferred tools are:
Sublist3rFindomainAmassEach of these tools (and others you might prefer) should be used combinedly to generate a list of subdomains and gain as big attack surface as possible.
Further down, httpx can be used to filter out a list of active subdomains and SubOver can be used to test for testing if the given subdomains are vulnerable to takeover or not.
Interesting Reports
Unbounce Subdomain TakeoverUberflipAmazon S3Azure Cloud ServiceFurther Reading:
FQDNDNS and Server TypesMore about dig commandDNS RecordsNS Subdomain TakeoverSubdomain TakeoversEd’s Takeover Guide










 Bengali (Bangladesh) ·
Bengali (Bangladesh) ·  English (United States) ·
English (United States) ·