.png)
Nautilus is a coverage guided, grammar based fuzzer. You can use it to improve your test coverage and find more bugs. By specifying the grammar of semi valid inputs, Nautilus is able to perform complex mutation and to uncover more interesting test cases. Many of the ideas behind this fuzzer are documented in a Paper published at NDSS 2019.

Version 2.0 has added many improvements to this early prototype and is now 100% compatible with AFL++. Besides general usability improvements, Version 2.0 includes lots of shiny new features:
How Does Nautilus Work?
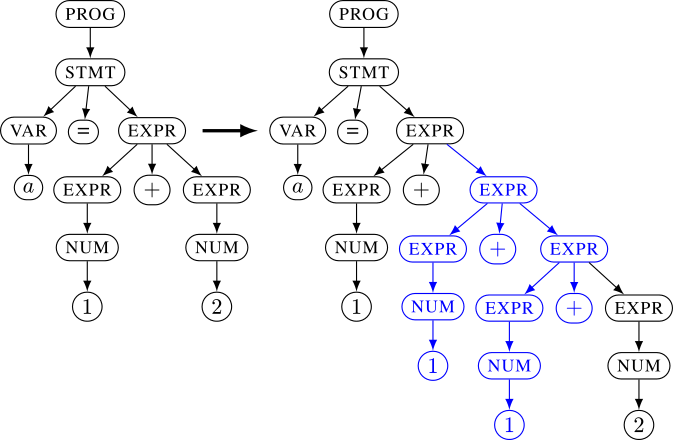
You specify a grammar using rules such as EXPR -> EXPR + EXPR or EXPR -> NUM and NUM -> 1. From these rules, the fuzzer constructs a tree. This internal representation allows to apply much more complex mutations than raw bytes. This tree is then turned into a real input for the target application. In normal Context Free Grammars, this process is straightforward: all leaves are concatenated. The left tree in the example below would unparse to the input a=1+2 and the right one to a=1+1+1+2. To increase the expressiveness of your grammars, using Nautilus you are able to provide python functions for the unparsing process to allow much more complex specifications.
Setup
Examples
Here, we use python to generate a grammar for valid xml-like inputs. Notice the use of a script rule to ensure the the opening and closing tags match.
To test your grammars you can use the generator:
$ cargo run --bin generator -- -g grammars/grammar_py_exmaple.py -t 100 <document><some_tag foo=bar><other_tag foo=bar><other_tag foo=bar><some_tag foo=bar></some_tag></other_tag><some_tag foo=bar><other_tag foo=bar></other_tag></some_tag><other_tag foo=bar></other_tag><some_tag foo=bar></some_tag></other_tag><other_tag foo=bar></other_tag><some_tag foo=bar></some_tag></some_tag></document>You can also use Nautilus in combination with AFL. Simply point AFL -o to the same workdir, and AFL will synchronize with Nautilus. Note that this is one way. AFL imports Nautilus inputs, but not the other way around.
#Terminal/Screen 1 ./afl-fuzz -Safl -i /tmp/seeds -o /tmp/workdir/ ./test @@ #Terminal/Screen 2 cargo run --release -- -o /tmp/workdir -- ./test @@Trophies
https://github.com/Microsoft/ChakraCore/issues/5503 https://github.com/mruby/mruby/issues/3995 (CVE-2018-10191) https://github.com/mruby/mruby/issues/4001 (CVE-2018-10199) https://github.com/mruby/mruby/issues/4038 (CVE-2018-12248) https://github.com/mruby/mruby/issues/4027 (CVE-2018-11743) https://github.com/mruby/mruby/issues/4036 (CVE-2018-12247) https://github.com/mruby/mruby/issues/4037 (CVE-2018-12249) https://bugs.php.net/bug.php?id=76410 https://bugs.php.net/bug.php?id=76244











 Bengali (Bangladesh) ·
Bengali (Bangladesh) ·  English (United States) ·
English (United States) ·